


求通俗解释下bandit老虎机到底是个什么东西?
单臂one-armed 和 多臂multi-armed 的
multi-armed bandit是一个非常经典的模型,当然,该模型有很多变种。我能查到的中文资料基本上都是浓浓的看不懂的翻译腔,用最最通俗的语言描述其中最基本的模型应该是这样的


假设你面前有这些色彩斑斓的按钮,按完每个按钮可能有两种情况:从机器里掉出一块钱,或者什么也没有发生
每个按钮出钱的概率是不一样的,也许那个红色的按钮有80%的概率会出钱,而那个右下角灰色的出钱概率为0,按到死都出不了一分钱,当然,在此之前,你对每个按钮出钱的概率的先验知识为0,也就是说你不知道每个按钮出钱的概率是多少。
而我们的目标是,在有限次的按按钮过程中(比如按1000次),获取的钱越多越好,应该以怎样的策略呢?
这个问题的麻烦之处在于,寻找最优的按钮和获得最大值之间的平衡!


举个例子
假设你开启上帝模式,知道这些按钮里概率最高的是红色按钮,有80%的概率出硬币,那最好的策略显然就是死命的对那个红色按钮怼,那么1000次尝试你会得到钱数的期望是800块,并且没有比这更好的策略了。
但在不知道这些知识的前提下,我们怎么做?小蠢是这样做的,每个按钮按三次,然后看出钱的多少,然后以后的每次都对着三次出钱最多的那个怼,但出钱概率70%的按钮也可能按三次一次都没出钱,出钱概率10%的按钮也可能连续按三次都出钱了,这样做显然不科学!
那增加实验次数行不行?我们每个按钮按50次,那么可以假设它收敛到期望了,但如果我们有20个按钮呢?1000次机会全给你做实验了,即使50次实验能得到所有按钮的准确的出钱概率,你也用光了1000次机会,然后把这些机会全部平均分给所有按钮,和你随机乱按没有区别。(摔桌,宝宝不玩了)
当然你也可以提出各种不同的策略、算法,但是归根结底,这个问题的本质就是寻找最优的按钮和获得最大值之间的平衡!
然后毕竟它只是个模型,传染病模型都可以用到和它根本不搭界的消息传播模型上,它能使用到的领域基本上就是这种寻找最优-获得最大值矛盾的地方,举个例子,临床试验:我们既要保证得出的每种药品治愈患者的概率较为准确,又要使得最后参加试验的患者治愈率最高;广告投放:我们在找到最能吸引点击率的广告的过程中又要使得,过程中广告的点击率尽可能最大。
有很多奇奇怪怪的策略来解决这个问题,比如其它楼链接中UCB族算法,当然还有用的比较多,可能性能更好的[1] Thompson sampling。
以上
reference:
[1] O. Chapelle and L. Li. An empirical evaluation of thompson sampling. In NIPS, 2011.
关于这个问题,我们想采用微软亚洲研究院资深研究员陈卫在中国理论计算机年会上的报告“在线组合学习”进行回答,解读多臂老虎机和组合在线学习之间的关系。
————这里是正式回答的分割线————
赌场的老虎机有一个绰号叫单臂强盗(single-armed bandit),因为它即使只有一只胳膊,也会把你的钱拿走。而多臂老虎机(或多臂强盗)就从这个绰号引申而来。假设你进入一个赌场,面对一排老虎机(所以有多个臂),由于不同老虎机的期望收益和期望损失不同,你采取什么老虎机选择策略来保证你的总收益最高呢?这就是经典的多臂老虎机问题。
这个经典问题集中体现了在线学习及更宽泛的强化学习中一个核心的权衡问题:我们是应该探索(exploration)去尝试新的可能性,还是应该守成(exploitation),坚持目前已知的最好选择?在多臂老虎机问题中,探索意味着去玩还没玩过的老虎机,但这有可能使你花太多时间和金钱在收益不好的机器上;而守成意味着只玩目前为止给你收益最好的机器,但这又可能使你失去找到更好机器的机会。而类似抉择在日常生活中随处可见:去一个餐厅,你是不是也纠结于是点熟悉的菜品,还是点个新菜?去一个地方,是走熟知的老路还是选一条新路?而探索和守成的权衡就是在线学习的核心。

多臂老虎机的提出和研究最早可以追述到上世纪三十年代,其研究模型和方法已有很多。其中一类重要的模型是随机多臂老虎机,即环境给予的反馈遵从某种随机但未知的分布,在线学习的过程就是要学出这个未知分布中的某些参数,而且要保证整个学习过程的整体收益尽量高。这其中最有名的一个方法是UCB(Upper Confidence Bound)方法,能够通过严格的理论论证说明UCB可达到接近理论最优的整体收益。
介绍了多臂老虎机问题,那组合在线学习和它之间有何关联呢?我们继续来看一下组合多臂老虎机(CMAB)问题。在组合多臂老虎机问题中,你一次拉动的不是一个臂,而是多个臂组成的集合,我们称之为超臂(super arm),原来的每个臂我们称之为基准臂(base arm),以示区别。拉完这个超臂后,超臂所包含的每个基准臂会给你一个反馈,而这个超臂整体也给你带来某种复合的收益。
那么如何解决组合多臂老虎机的问题呢?你可能首先想到的就是把每一个超臂看成是经典多臂老虎机问题中的一个臂。但是超臂是多个基准臂的组合,而这样组合的数目会大大超过问题本身的规模——组合问题中经典的组合爆炸现象,因此传统的方法并不适用。所以在线学习不能在超臂这个层次进行,而需要在基准臂层次上进行,并需要与离线组合优化巧妙地结合。我们在ICML2013的论文[2]中给出了组合多臂老虎机的一般框架和基于UCB方法的CUCB算法。CUCB算法将组合优化和在线学习无缝对接实现了前面图示中的反馈回路。较之前的涉及组合多臂老虎机的研究,我们的模型适用范围更广,尤其是我们通过给出收益函数的两个一般条件,能够涵盖非线性的收益函数,这是第一个能解决非线性多臂老虎机问题的方案。我们的工作,包括之后我们和他人的后续工作,都强调对在线学习部分和离线优化部分的模块化处理和无缝对接。也即我们将离线优化部分作为一个黑盒子神谕(oracle),这部分可以由具有相关领域知识的专家来完成。而一旦离线优化问题可以精确解决或近似解决,我们就可以把这个离线算法当作黑盒子拿过来和我们在线学习方法相结合,达到有严格理论保证的组合在线学习效果。这使得我们的方法可以适用于一大批已经有离线优化算法的组合在线学习问题,比如最短路径、最小生成树、最大匹配、最大覆盖等问题的在线学习版本,而不需要对每个问题单独再设计在线学习算法。
在论文“Combinatorial Multi-Armed Bandit: GeneralFramework, Results and Applications”中,我们进一步将组合多臂老虎机模型扩展为允许有随机被触发臂的模型。这一模型可以被用于在线序列推荐、社交网络病毒式营销等场景中,因为在这些场景中前面动作的反馈可能会触发更多的反馈。然而在其理论结果中,我们包含了一个和触发概率有关的项,而这个项在序列推荐和病毒营销场景中都会过大,造成在线学习效果不好。在今年刚被录取的NIPS论文“ Improving Regret Bounds for Combinatorial Semi-Bandits with Probabilistically Triggered Arms and Its Applications”中,我们彻底解决了这个问题:一方面我们论证了序列推荐和病毒营销等满足某种特定条件的问题都不会有这个不好的项,另一方面我们指出在更一般的组合多臂老虎机中这个项又是不可避免的。这是目前研究可触发臂的组合多臂老虎机中最好的一般结果。
除此之外,我们还在与组合多臂老虎机相关的方面做了若干工作,比如如何在反馈受限情况下达到好的学习效果;如何解决先探索再找到最佳方案的组合探索问题;当离线优化基于贪心算法时,如果更好地将离线贪心算法和在线学习相结合;如何在有上下文的场景中解决组合序列推荐问题;以及当超臂的期望收益取决于每个基准臂的随机分布而不仅是每个基准臂的分布均值时,如何同样有效地进行组合在线学习。
————这里是回答结束的分割线————
以上回答摘选自微软研究院AI头条,组合在线学习:实时反馈玩转组合优化。
感谢大家的阅读。
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信 (ID:MSRAsia) 账号,了解更多我们的研究。
这篇回答节选自本人在知乎专栏上正在持续更新的一个系列文章的引子:
覃含章:在线学习(MAB)与强化学习(RL)[1]:引言
要了解MAB(multi-arm bandit),首先我们要知道它是强化学习(reinforcement learning)框架下的一个特例。至于什么是强化学习:
我们知道,现在市面上各种“学习”到处都是。比如现在大家都特别熟悉机器学习(machine learning),或者许多年以前其实统计学习(statistical learning)可能是更容易听到的一个词。那么强化学习的“学习”跟其它这些“学习”有什么区别呢?这里自然没有什么标准答案,我给这样一个解释(也可见Sutton & Barto第二章引言):在传统的机器学习中,主流的学习方法都是所谓的“有监督学习”(supervised learning),不管是模式识别,神经网络训练等等,你的分类器并不会去主动评价(evaluate)你通过获得的每个样本(sample)所进行的训练结果(反馈),也不存在主动选择动作(action)的选项(比如,可以选择在采集了一些样本之后去采集哪些特定的样本)。意思就是,在这些传统的机器学习方法中(实际上也包括其它无监督学习或者半监督学习的很多方法),你并不会动态的去根据收集到的已有的样本去调整你的训练模型,你的训练模型只是单纯被动地获得样本并被教育(instruct,作为对比,active learning主要就是来解决这一问题的)。
而强化学习主要针对的是在一个可能不断演化的环境中,训练一个能主动选择自己的动作,并根据动作所返回的不同类型的反馈(feedback),动态调整自己接下来的动作,以达到在一个比较长期的时间段内平均获得的反馈质量。因此,在这个问题中,如何evaluate每次获得的反馈,并进行调整,就是RL的核心问题。
这么讲可能还比较抽象,但如果大家熟悉下围棋的AlphaGo,它的训练过程便是如此。我们认为每一局棋是一个episode。整个的训练周期就是很多很多个epsiode。那么每个episode又由很多步(step)构成。
动作——指的就是阿法狗每步下棋的位置(根据对手的落子而定)
反馈——每一次epsiode结束,胜负子的数目。
显然,我们希望能找到一个RL算法,使得我们的阿法狗能够在比较短的epsisode数目中通过调整落子的策略,就达到一个平均比较好的反馈。当然,对这个问题来说,我们的动作空间(action space,即可以选择的动作)和状态空间(state space,即棋盘的落子状态)的可能性都是极其大的。因此,AlphaGo的RL算法也是非常复杂的(相比于MAB的算法来说)。
至于什么是MAB/老虎机问题:
我们先考虑最基本的MAB问题。如上图所示,你进了一家赌场,假设面前有 









这就是最经典的MAB场景。那么问题的核心是什么呢?自然,我们应该要假设
这里当然还有个重要的统计学/哲学问题:即我们是贝叶斯人(Bayesian)还是频率学家(frequentist)。对贝叶斯人来说,我们在一进入赌场就对每台老虎机扔钱的概率

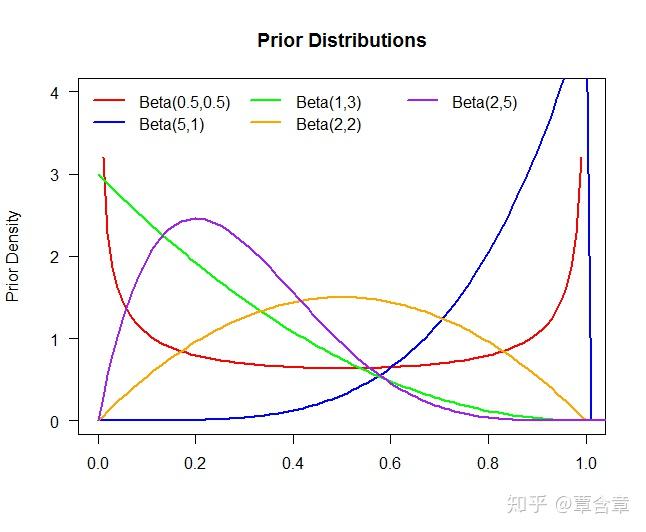
而如果你是频率学家,就没什么先验或者后验分布了,你假设你一开始对这些机器的吐钱概率一无所知。你认为每个机器的 

本节最后,我们指出这个MAB问题可能的一些(更复杂的)变种。首当其冲的在于,我们前面的讨论默认了环境是不会变化的。而一些MAB问题,这个假设可能不成立,这就好比如果一位玩家发现某个机器的
另外MAB有一类很重要的变种,叫做contextual MAB(cMAB)。几乎所有在线广告推送(dynamic ad display)都可以看成是cMAB问题。在这类问题中,每个arm的回报会和当前时段出现的顾客的特征(也就是这里说的context)有关。同样,今天我们不展开讲cMAB,这会在之后花文章专门讨论。
另外,如果每台老虎机每天摇的次数有上限,那我们就得到了一个Bandit with Knapsack问题,这类问题以传统组合优化里的背包问题命名,它的研究也和最近不少研究在线背包问题的文章有关,之后我们也会专门讨论。还有很多变种,如Lipshitz bandit, 我们不再有有限台机器,而有无限台(它们的reward function满足利普西茨连续性)等等。。题主既然要最通俗的版本,所以这里就不赘述了,有兴趣深入了解的同学们可以考虑关注我的专栏系列文章,主要是让大家有更好的准备去读一些专门的书籍文献~
我从优化角度来说 bandit ,bandit 数学讲严格太多概率计算,十分不直观,所以用不太严谨的方式说。
问题定义:假设收益期望 ![Q(a)=\mathbf{E} [r|a]](https://hejiyule.org/wp-content/uploads/2023/07/hs100d.jpg)

![a\in[1,K]](https://hejiyule.org/wp-content/uploads/2023/07/G2laBBe3.jpg)



举个 toy 点的例子,我们不妨给 a 空间分成三个桶 

![a_1=[r_1, r_2, r_3] \\ a_2=[r_4, r_5] \\ a_3=[r_6, r_7, r_8, r_9]](https://hejiyule.org/wp-content/uploads/2023/07/9uzu72aTCZ.jpg)

剩下的就是用利用这些样本,依靠函数近似拟合出 Q(a),比如平均法: 

或者更加复杂的非线性回归方案:


然后依靠泛化,取 

换到互联网的说法,就是上线一个流氓策略,调戏用户无限轮,拿到足够的标签,然后跑一个有监督回归任务,只要系统兜底不被击穿,暴力监督方案是一个非常落地其符合国情的算法。
显然,暴力遍历会在前期产生严重亏损,数学上,我们会用利用悔恨度量这种亏损: 
也就是说,我们搜索最优点,从一无所知到有最终找到
下面用非常不严谨的数学,说下悔恨的渐进性质,以及策略迭代的方式。首先,每次迭代一轮策略,我们都可以计算每个 a 下的平均悔恨,比如迭代到第 9 步,有:


总的悔恨为 





衡量,根据这个 bound,每个 a 对应的悔恨有这么一个不等式:


一般来说,T 步下的悔恨都有这么一个通用 bound,N_a 是 a 下的累计样本数:


所以,要找到策略让悔恨尽量小,等效于不断调整 

举个例子,如果配比是 1:1:1,一般只有随机策略才产生这种配比,那么悔恨上界几乎正比于 T,十分不好。
显然,新来一个样本,T+1 步的合理策略,就是找悔恨最小的那个桶,然后将其放入,实际就是选择 


不等式的右边,是要将 Q(a) 这种未知量,依靠高置信度因子 





这种情况下,每个桶当中不仅累计了收益,还累积用户特征:
![a_1=[x_1, x_2, x_3] \\ a_2=[x_4, x_5] \\ a_3=[x_6, x_7, x_8, x_9]](https://hejiyule.org/wp-content/uploads/2023/07/0k7998LxJ.jpg)
每个桶里,每个用户反馈分别为:
真实收益函数变成 








如果利用 UCB 去调桶内用户样本配比,新用户将会按照如下方式进入桶内:


说的通俗点,就是先查相似用户,然后再根据其它用户的反馈,估算新来用户的收益,然后加上点不确定度,合并以后最大化,然后把用户塞进去。有趣的是,单纯用户相似性加权这一点,在各种推荐里面都出现,不论数学出发点,还有论证有多绕,总是奇迹般存在这个影子。
理论上,contextual bandit 里面的悔恨非常依赖 S 函数,对于线性的 bandit,S 函数就是某种点乘相似度,不论 S 设计有多复杂,悔恨上界总会被拆分成两部分:


第一部分的偏差,是我们建模的预估模型 q 没法拟合真实的 reward Q,模型容量低造成的,第二部分就是标准 UCB 带来的 bound,论文一般只计算后者,前者被假设没了。
从上面不太严谨的 bound 也可以看出来,真的做应用的时候,模型拟合不动真实收益函数,前期损失堪比随机策略。所以 Lin-UCB 乃至 sup-Lin-UCB 这些算法,都默认线性能够拟合收益。也导致实际使用当中,收益函数不能够做的太复杂,比如所有兜底惩罚不能够写进收益,就是担心过于复杂的决策边界,会让模型拟合不动,这是很繁琐的 reward engineering 的问题。
如果想提高拟合能力,我们需要复杂一点模型,比如 kernel -UCB,思路也比较简单,就是给特征套一个核函数 

当然,后面还有如何通过打点日记进行 bandit 的训练,也叫 logged bandit,由于有海量数据做保证,所以深度学习用在 bandit 里头也是有可能的。不过,后者的数学合理性,我目前存疑,故此不展开细说。
在说bandit之前先考虑一个实际问题:假设你来到一个新的城市,你刚开始选择去哪吃饭可能随机选一选,你大概会知道哪些店比较符合你的口味。当你有了一些基本的判断之后,你是会选择吃原来觉得好吃的店呢?还是探索你从来都没有去过的店呢?从来都没有去过的店你可能会觉得更好吃,也有可能不会。人的选择一般都是探索一点点,大部分时候都会选择以前觉得还可以的店。这中间就有个度的问题。在计算机中怎么量化这个度呢,其实还是蛮难的。
可以看出上述问题明显是一个决策性问题,并且是单步决策问题,在强化学习中当前所采取的动作会影响之后的决策,甚至有时候为了获取未来期望的最大回报,我们当前决策可能并不会采取能够获得及时奖励最大的那个动作,像下围棋这种是连续决策问题。单步决策就只有一个状态,选择某个动作,然后游戏结束,开始新一轮游戏。因此Multi-armed Bandit相关的算法的关键都在于如何平衡探索和利用(trade off exploration and exploitation)。这类问题的建模过程可以被用于其它领域,比如像逛淘宝,买东西等等都可以建模成此类问题。甚至可以用于药物研发:
在药物设计问题上面,开发一款药,不同的成分比例对病人的实际应用效果不一样,那究竟是什么样的比例能够把病人快速治好呢?此时动作就变成了选择某个成分的药品,奖励来自病人的反馈(是否痊愈,以及痊愈程度),我们要做的事情就是用最少的病人,发现这个药物的成分的最佳比例。
bandit老虎机描述的就是这样一类问题的数学模型。(下文对其基本算法展开说明):
让我们考虑一个最基本的Stochastic Bandits问题,定义如下:
状态集合为single state:

arms,采取某个动作(或者选中某个arm)时,将会得到一个及时奖励的反馈,通常是属于![[0,1]](https://hejiyule.org/wp-content/uploads/2023/07/8Vgs4I4.jpg)



与传统的强化学习不一样的地方在于这里没有转移函数(transition function),因为其只有一个单个的状态。智能体需要学习的是随机的奖励函数stochastic reward function。也就是说智能体在采样过程中,依据采样数据学习奖励函数分布,从而进一步指导接下来的动作(如果知道某个arm能够获得更多的奖励,那之后就一直选择这个arm,就能获得更多的奖励)。
对于多臂老虎机,描述起来都是比较简单的一个问题,但是最优解求解比较困难,对于上述问题看起来就没有什么思路。
- Greedy strategy:
多想一下可能会有一个贪婪策略(greedy strategy),就是选择当前平均奖励最高的那个arm,但是这种贪婪策略就没有考虑探索,比如有两个arm,当选择了其中一个arm-1这次得到奖励1,而另一个arm-2奖励为0,之后依据贪婪策略就一直选择arm-1,但arm-1实际的奖励为1的概率为0.1比arm-2奖励为1的概率0.9低呢?只不过刚好第一次被选中了而已,就很容易丢失掉探索,导致得到一个次优解。


而arm,而
greedy策略,也就是选择当前平均奖励最高的那个arm。由此可以看出收敛率(多快找到最优的arm)会取决于

我们要衡量算法的好坏的话,需要定义一个指标,遗憾值(Regret)。
定义
arm的实际平均奖励值(或者称之为期望奖励)。如果我们知道了每个arm的平均奖励值,那我们可以找到具有最高平均奖励的那个arm,即:



也就找到了具有最高平均奖励所对应的动作


但是我们并不知道每个arm的实际真实平均奖励loss,用于衡量采取某个动作的好坏。对于每个动作与最优的动作比较,其二者之差可以定义为loss:


time step下的期望累计遗憾可表示为:


我们之前在讨论strategy的时候说过regret时如何来进行理论分析呢?分析其本质规律。
- 如果
time step足够大的话,
arm都会后悔regret),此时的期望累计遗憾值
- 如果
time step增加,time step足够大的话,time step的增加,次优解会逐渐减少,此时的期望累计遗憾值





线性级的遗憾值无法收敛,是无法得到最优解的,只能得到一个次优解。因此我们期望说能够找到一个遗憾值能尽快收敛的策略,若
那经验平均奖励
upper bound),如

upper bound对应的那个arm,即 
upper bound收敛的时候,由于一直选取最大的upper bound对应的那个arm,我们得到的最优动作就是




此时的问题就在于我们通过sample的方法是无法得到确定的upper bound的。就是基于采样的方法并不能得到真实的每个arm对应的奖励分布。我们可以采用概率的方法来表示,就是在采样过程中,
Hoeffding’s inequality)有:


其中 arm a尝试的次数。





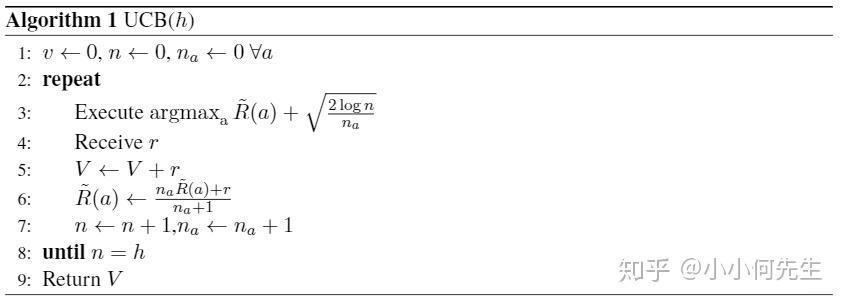
尽管上述算法理论上有收敛性保证,但是需要sample多次。
Bayesian Bandits能够更好地描述不确定性,在智能体平衡探索和利用的时候也是在决策不确定性,当智能体选择探索的时候不确定性更大一点,当选智能体择利用以往经验知识的时候不确定性就更小一点。用贝叶斯的方法来描述这种不确定性分布就是bayesian bandits。另一种能够获取更多状态信息的bandits方法称之为Contextual Bandits。
在开始贝叶斯多臂老虎机之前我们需要先定义贝叶斯学习(Bayesian Learning)。
当我们采取某个动作


![R(a)=E[r^{a}]](https://hejiyule.org/wp-content/uploads/2023/07/FKs5Te6Ci.jpg%3DE%5Br%5E%7Ba%7D%5D)



因此我们可以把这种不确定性表述为一个先验分布


bandits的奖励分布。那这个后验分布怎么求呢?依据贝叶斯定理有:






假设我们已经求得这个后验分布,我们就可以去估计下一个时刻的奖励

而我们关心的是每个arm的平均奖励

到此,我们就可以计算最优策略。与之前的UCB算法对比:
UCB解决arm奖励分布不确定性用的是bound的方式,通过迭代求解bound来获得真实的期望奖励
- Bayesian techniques:并不通过求解
upper bound,而是直接对其进行建模求解,直接求解arm奖励分布的概率。 - Coin Example:

举个例子,假设我们有两枚硬币

head朝上的概率不一样,可表示为:



期望在
head的次数。那每次掷币我们因该选择哪个coin呢?可以量化每个coin的奖励分布







若我们知道coin。设定beta分布,则有:


其中
head的次数,
tails)的次数,能拿到的奖励的期望值为


获得了



和

当我们能够获得后验分布时,通过采样可以获得每个动作

然后估计经验平均奖励:

选择动作的时候抽取能获得最大的奖励所对应的那个action 


与Greedy Strategy对比,两者的不同就在于经验平均奖励一个是来自后验分布概率计算出来的

Thompson Sampling基于后验概率算出来的奖励是具有不确定性的,因此探索程度会比贪婪策略更好,而随着观察数据的增多,模型越来越准确,这种探索也会随之减少。


在很多场合Context会提供更多的额外信息,比如像个性化推荐系统,Context会包含用户的年龄,性别,居住地等信息,而这些信息对个性化推荐系统都能起到辅助的作用。
contextual bandits用数学的方式描述为:


- lionking老虎机

- 奖励空间





同样的是没有状态转移函数的。而我们要做的是找到一个策略









在线性近似的情况下采用贝叶斯的方法对其进行求解。假设参数



一旦我们知道了参数


基于贝叶斯定理可以计算后验概率求得参数



其中






lionking老虎机 lionking老虎机lionking老虎机


